问题所在
我们的大脑不会平等地记住所有事情。
今天早上喝的咖啡?正在快速消退。婚礼那天?几十年后依然清晰。上个月头脑风暴中的突破性想法?因为你一直在基于它构建,所以仍然新鲜。
大脑会自然地分清轻重缓急。这不是缺陷:正因为会遗忘,记忆才能长期保持有用。
可大多数数字记忆系统对所有信息一视同仁。三年前做的决定和今天刚想通的洞察摆在一起,以同样的权重争夺你的注意力。
随便搜点东西,你就会被一堆轻重不分的结果淹没。
如果…
要是个人记忆系统也能像大脑这样工作,会怎么样?
最近用得多的知识自然冒到前面,旧的、用不上的安静退后。
你问一句「上个季度我们做了什么决定?」,拿回来的真就是上个季度那几条。
我们是如何做到的
我们研究了认知科学家如何建模人类记忆,特别是卡内基梅隆大学的 ACT-R 和 叶峻峣 的 FSRS,后者驱动着像 Anki 这样的现代间隔重复系统。
在这项研究的基础上,我们做了一个实用的记忆衰减模型:
-
时效性:最近用过的记忆得分更高。我们用大约 30 天半衰期的指数衰减,昨天的记忆排得比三个月前高得多。
-
频率强化:反复用到的记忆会变得更牢固。你的行为在告诉系统什么重要。
-
重要性兜底:真正要紧的基础知识不会彻底沉下去,哪怕一直没碰过。
-
反馈塑造相关性:借鉴 FSRS 追踪「是否记得」的思路,我们记录展示次数、点击和停留时间。点得多,说明这条确实有用;读得久,说明内容值得看。
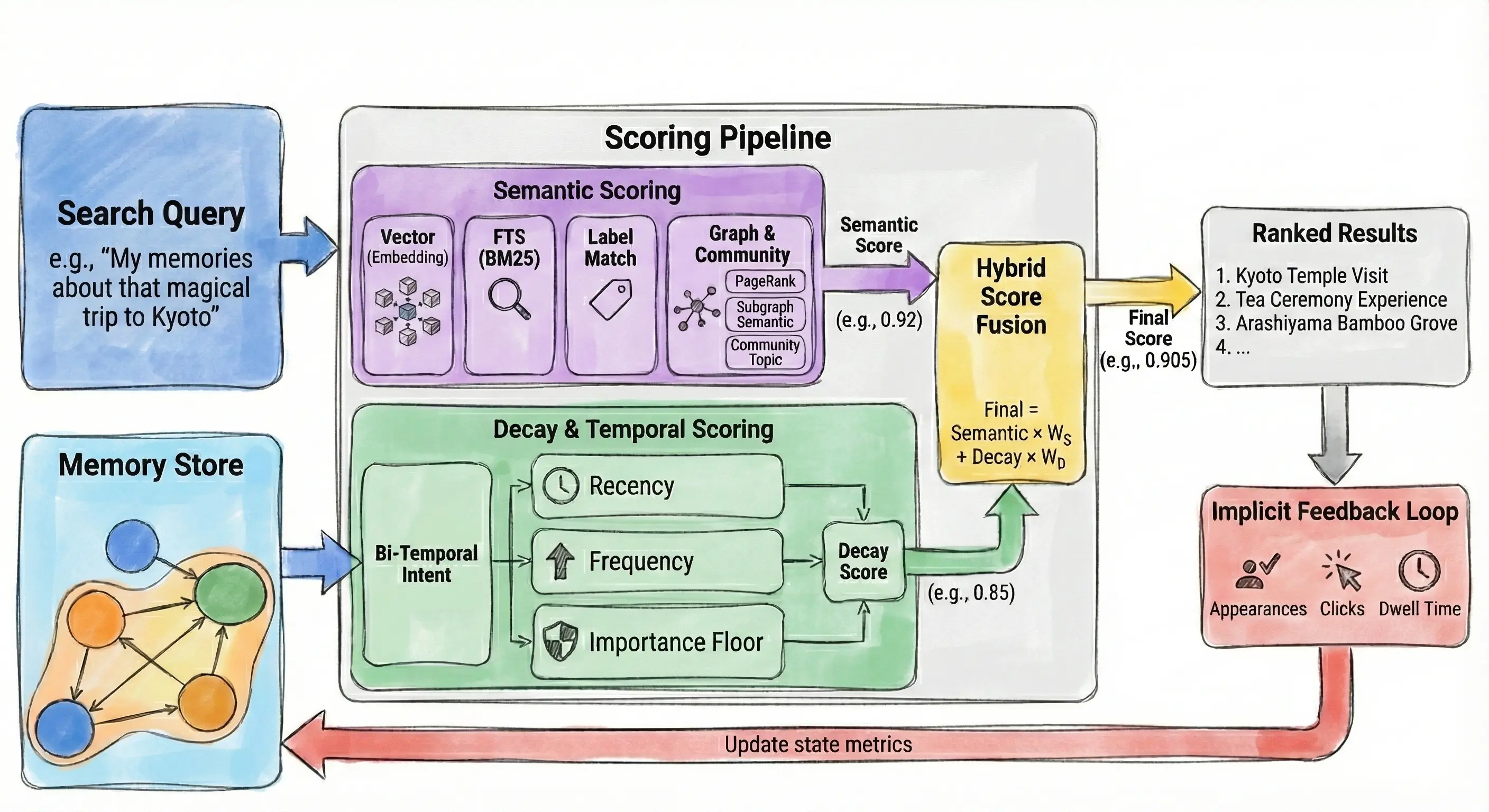 Nowledge Mem 评分管道
Nowledge Mem 评分管道
这样一来,搜索更像回忆,而不像考古。真正相关的内容,会在你需要它的时候自己冒出来。
理解时间
相关性之外,还有一类难题:跟时间有关的查询。
比如这几种搜索:
- 「我们迁移数据库之前发生了什么?」
- 「去年第三季度的记忆」
- 「关于认证的最近洞察」
这些不是单纯的关键词搜索,问的是事情什么时候发生的。
棘手的地方在于,时间其实有两种。
一种是事件时间,也就是事情真正发生的时间。一条关于 2020 年某个决定的记忆,事件时间就是 2020 年。
另一种是记录时间,也就是你把它存下来的时间。今天你才记下那个 2020 年的决定,它的记录时间就是 2025 年。
所以「关于 2020 年那件事的最近记忆」是有讲究的:指的是你最近才存下来、内容关于 2020 年的东西。
Nowledge Mem 现在分得清这两者。你说「2020 年前后」或者「去年初」这种模糊的说法,它也能接住,给出靠谱的结果。
这意味着什么
-
噪音更少。旧的、没用过的记忆不会再挤占结果。需要的时候它们还在,但会给更新的知识让路。
-
相关性更好。一个查询命中好几条记忆时,你一直在用的那几条会排在前面。
-
搜索带上了时间感。「上个季度我们做了什么决定?」这类问题,现在真的问得了。
-
自己会归整。不用手动归档或删除,记忆会照着你实际怎么用,自行排好次序。
下一步
这只是整个系统里的一层,影响却铺到了方方面面。衰减模型更准、对时间理解得更细,搜索结果、agent 的回忆、每天早上的简报,都会更贴近知识在真实使用中变化的样子。
想看技术细节,可以读搜索与相关性文档,里面有评分系统的完整说明。