做 Skills 的时候,Mem 顺手给自己做了个最好的 demo。
我们的开发记录本来就接在 Mem 里。它从里面认出一套我们反复在用、却从没正经写下来的办法,写成了一条 Skill,还附上出处。之后我们让系统去改进这条 Skill:它从证据里建了一套小评测,跑了两轮改法,最后一个都没留下,因为没有一版比原来更好。
没改,反而是我们最信它的地方。不过先说那套办法本身。
它认出的那套办法
先做一套会失败的评测,把每一步发生了什么记下来,看清到底卡在哪,只改那一处,再重新跑。
这句话听起来很普通。但结果一不对,人最容易跳过的就是它。本能反应是调 prompt、换模型、改阈值,或者让系统多推几条。看起来很忙,其实你不知道哪一步真的变好了。
这套办法我们最近用过两次。一次是在 con 上,那是我们在做的终端,让 AI agent 直接驱动一个真实 shell。那边的评测一开始 15 个用例只过 5 个,最后拉到 15/15 的不是更强的模型,而是评测本身跟着任务一起长,诚实到能看清每个失败到底卡在哪。另一次是在 Mem 自己身上:测 Skills 推荐能从图谱里找回多少真实的 procedure,把漏斗变得可见,一次只修一个约束。
Mem 从这些记录里看出了共同的模式,写成了一条 Skill:build-a-harness-optimize-loop。
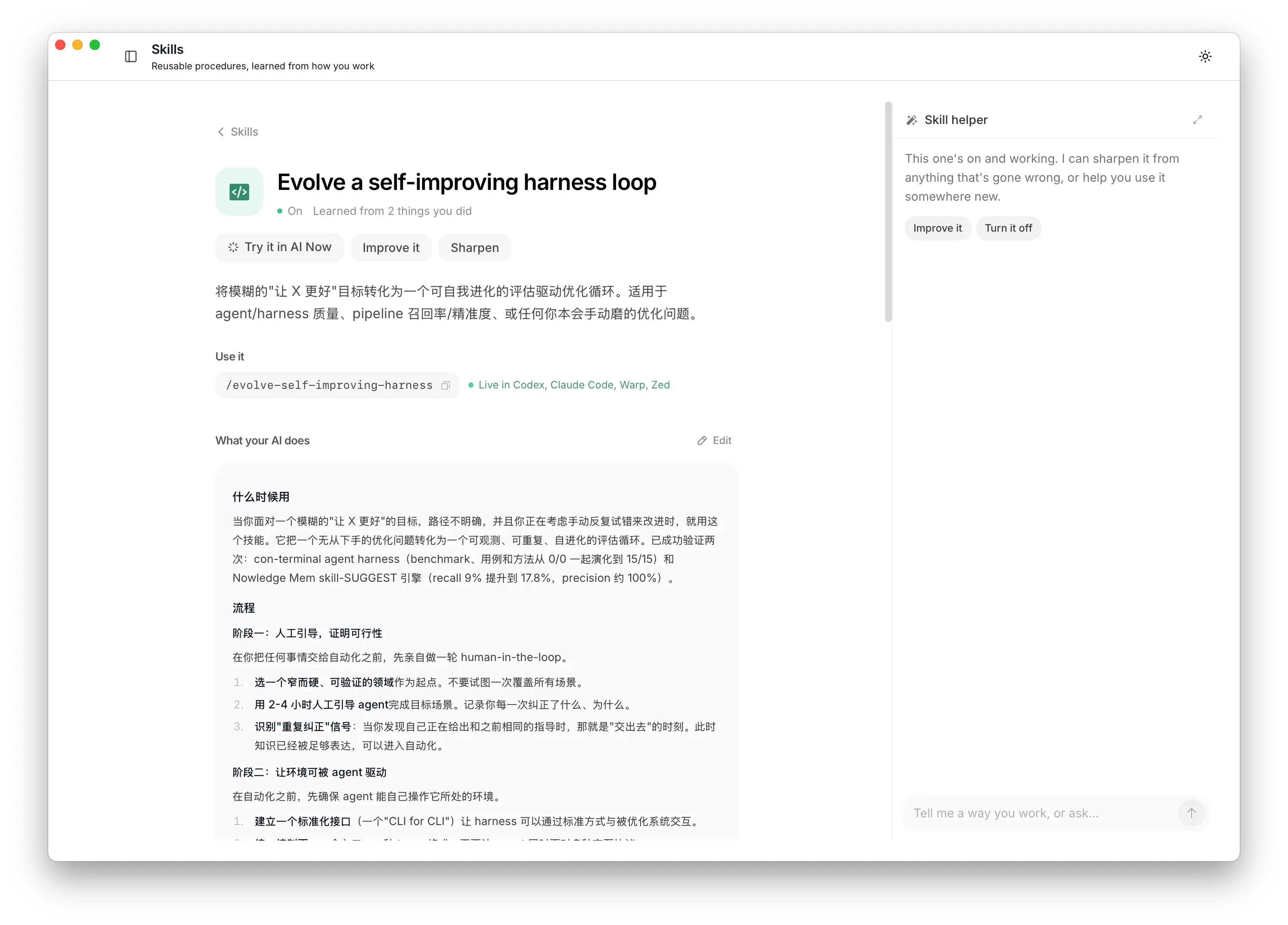 harness loop Skill 的详情页
harness loop Skill 的详情页
它没有写「做事要有评测」这种空话。它写的是具体动作:先量什么,为什么每一步要留记录,什么时候只改一个地方,什么时候不要急着扩大范围。这正是我们想要的样子:方法来自真实工作,写出来 Agent 能直接照着做。
然后,它拒绝乱改
我们又让 Mem 去打磨这条 Skill。
它从这条 Skill 自己的证据里补出测试用例,试了几版改法,逐一和当前版本比。两轮下来,没有一版更好,所以什么都没发生:没有待应用的新版本,没有静默覆盖,也没有为了显得「有进展」硬塞一版。
这个结果很安静,但它是对的。文章改坏了,最多难看一点;Skill 改坏了,Agent 下次会真的按它去做,因为 Skill 一旦打开,Agent 是真的会照着做的。一个会自我改进的系统,得能变好,也得知道什么时候该停。改不出更好的,就不改。
Skill 到底是什么
这件事正好能说清,v0.9 里我们为什么把三类东西分开。
记忆记录发生过的事、做过的决定、学到的经验。
「回答简短点」是规则,它应该一直生效。「这个项目里别手改自动生成的 API 文档」也是规则,它约束 Agent 的行为。
「发版时先提交子仓库,再提交父仓库指针」是 Skill。它改变的是做事顺序,Agent 不知道这一步,repo 状态就容易乱。
判断只用一个问题:它会让 Agent 下次做事时,具体哪一步变得不一样? 答不上来,就不该变成 Skill。
Skill 的可信来自出处,不来自文笔。Mem 在你真实做过的工作里找反复出现的做法:一次排查、一段发版、一轮 review、一个你踩过坑才知道要加的检查。每条建议都指回当时发生过的事。建议默认是关着的,开不开由你,因为错的 Skill 会让下一次运行变得更糟。
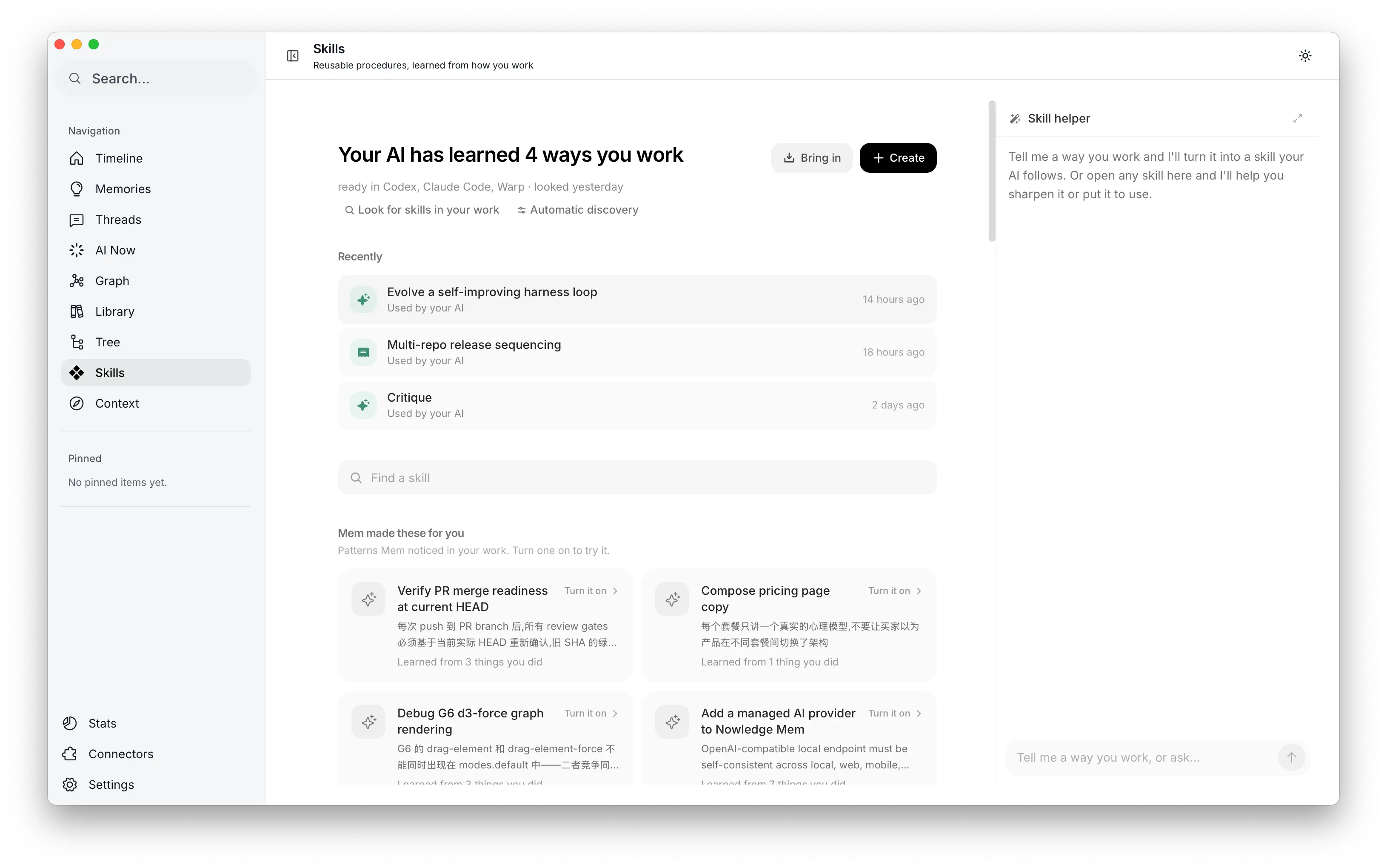 Nowledge Mem 里的 Skills
Nowledge Mem 里的 Skills
v0.9 里你会看到什么
AI 给什么都能写出一份像样的 checklist,但大部分不值得留:好模型本来就会写通用版。所以 Skills 页面应该很安静。
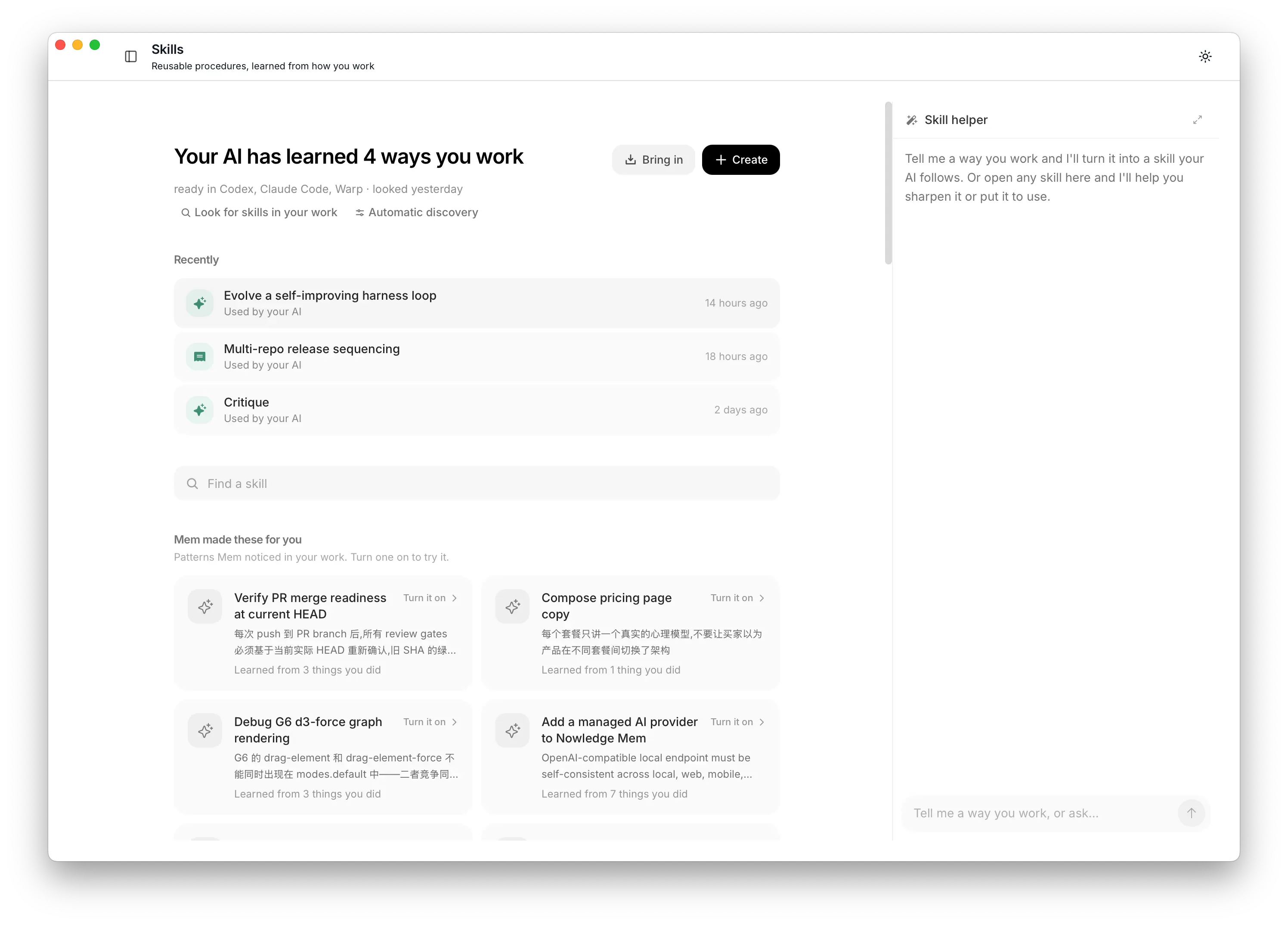 Skills 列表里的 harness loop Skill
Skills 列表里的 harness loop Skill
建议要少,每条都要有来处,并且回答三件事:
- 它来自哪段真实工作?
- 打开后,Agent 的哪一步会变得不一样?
- 为什么 Mem 认为这条值得留下?
如果你认得这条做法,也信得过它的出处,就打开。之后连接到 Mem 的 Agent 就能在合适的时候读到它;以后再被打磨,也要先过同一道关:新版本得证明自己更好。
这就是 v0.9 的 Skills:把你真的做对过的那一步,变成 Agent 下次也能做对的能力。这一版的完整介绍在 v0.9 发布文章。